
Table of Contents
What is Bias-Variance Tradeoff?
The bias-variance tradeoff is a key machine-learning concept that describes model bias and variance. The difference between a model’s predictions and the target variable’s true value is bias. Variance measures a model’s forecast variation across data samples.
High-bias models make systematic errors, while high-variance models make random errors. Models with low bias possess high variance and models that have low variance have high bias.
Machine learning seeks a model with low bias and variance. However, this is often impossible, thus a trade-off must be made.
What is high bias and low variance vs high variance and low bias? provide an example to demonstrate
High bias, low variance
A biased model may make systematic errors. A simplistic model that cannot capture data complexity can cause this. A linear regression model may be too simplistic to describe the relationship between features and a target variable. The model’s forecasts will be consistently wrong.
The forecasts of biased models are generally overconfident. This is because they ignore data uncertainty. Thus, they are more prone to forecast target variable values that are too far off.
High variance, low bias
A high-variance model may create random errors. This can happen if the model is overly sophisticated and overfits the training data. A multi-branch decision tree model may be too complex for a little dataset. Thus, the model will predict differently on different training set samples.
High-variance models generally underestimate forecasts. Due to poor generalization to fresh data. As a result, they are more likely to predict values near to the training data but not the target variable.
Let’s look at this example
Take a basic property price prediction example. A biased model may forecast the same price for every house. The model would be biased yet have low variance. Even for similar houses, a high-variance model may predict a different price. A very variable, low-bias model.
A model that balances bias and variance is optimal. This model could predict accurately without systematic or random errors.
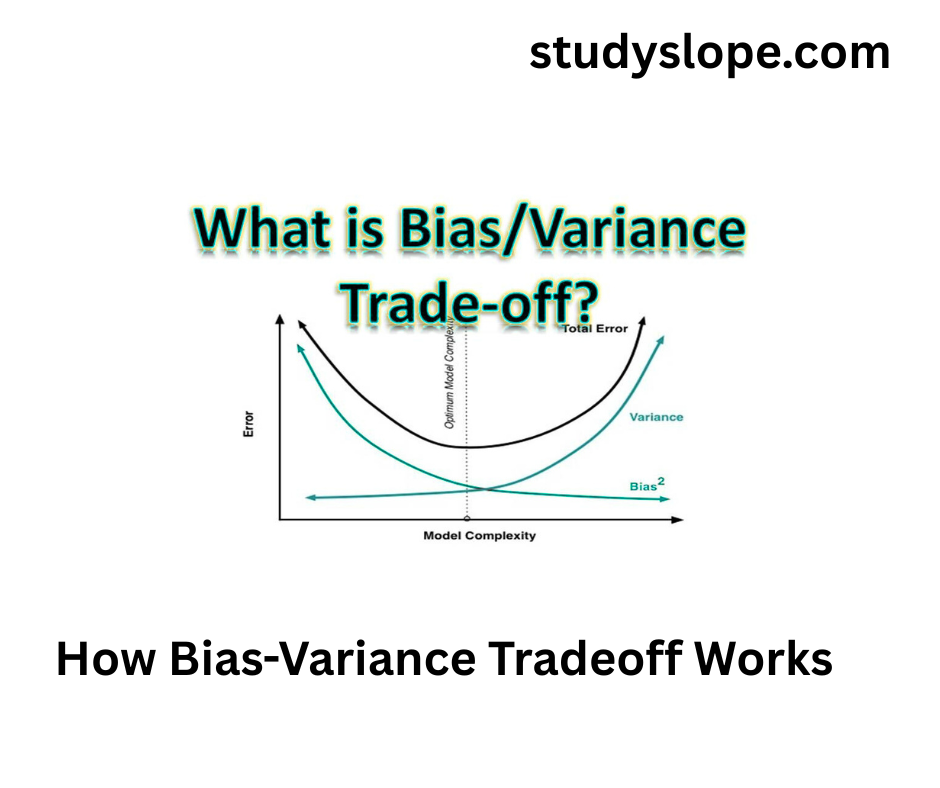
How Bias-Variance Tradeoff Works
When building machine learning models, it is important to understand that complex models can capture intricate patterns in the data but may also overfit to noise, resulting in high variance. At the same time simpler models may have high bias, leading to an oversimplified representation of the data.
The bias-variance tradeoff indicates that increase in the complexity of a model, its variance decreases, and its bias increases. On the other, as we decrease the model’s complexity, its variance increases, but its bias decreases. The main aim is to maintain the balance between these two aspects to create a model that performs well on new, unseen data.
Importance of Bias-Variance Tradeoff
Bias and Variance The tradeoff is a crucial aspect of the field since it has a significant impact on the predicted accuracy of a machine learning model. While a model with strong bias will consistently produce predictions that are far from the actual values, a model with high variance will consistently produce predictions that deviate significantly from the real values when it comes to training datasets. The model’s ability to apply its conclusions to new, unidentified data is reduced in both cases.
Organizations must first comprehend and optimize the bias-variance tradeoff in order to develop machine learning models that are both accurate and straightforward. Robust models that are less likely to overfit and more likely to generate accurate predictions on real-world data ultimately lead to better decision-making and business outcomes.
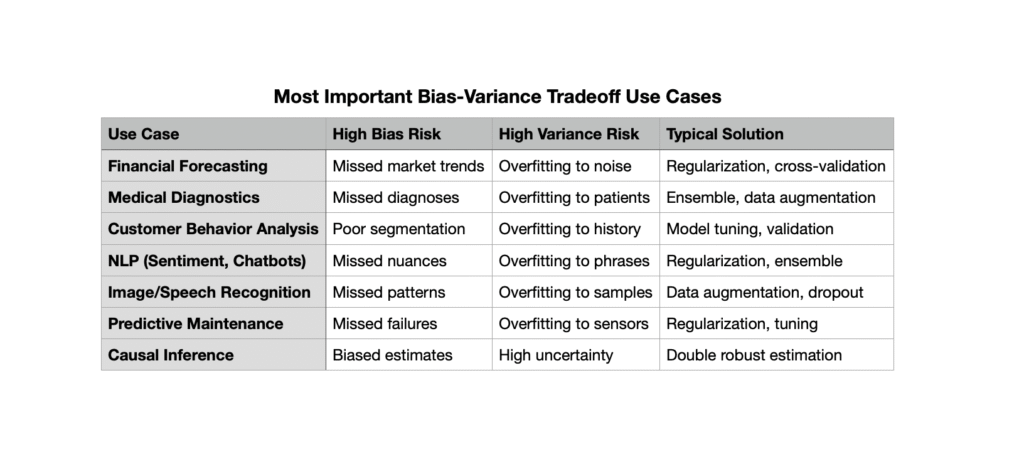
Most Important Bias-Variance Tradeoff Use Cases
The bias-variance tradeoff is a foundational concept in machine learning and statistics, directly impacting model performance and generalization. Here are the most important real-world use cases where managing this tradeoff is critical:
People also View: What is dirty data?
Technologies Related to Bias-Variance Tradeoff
Here are some tools and techniques for understanding and dealing with the bias-variance tradeoff:
Regularization (Lasso, Ridge) stops models from becoming too complex by punishing large coefficients. This lowers bias, variance, and overfitting without raising bias too much.
Cross-validation (like K-Fold) checks how well a model works on different sets of data to find and balance bias and variance. This makes the model better at making predictions on new data.
Ensemble Methods (Bagging, Boosting, Random Forest): These methods use more than one model to lower variance and improve predictive performance with only a small increase in bias.
Grid search and random search are two ways to tune hyperparameters. They help you find the best model parameters that give you the best balance between bias and variance for a given dataset.
Adding more training data: This helps lower variance and overfitting by allowing complex models to generalize better.
Choosing a model: You can choose between simple models, like linear regression, which has high bias and low variance, and complex models, like decision trees, which have low bias and high variance, depending on the data and the use case.
Early Stopping: This stops training when performance on validation data starts to go down. This stops iterative algorithms (like neural networks) from fitting too well to the data.